满嘴都是糖果
Redis 五种核心数据类型及其使用的数据结构
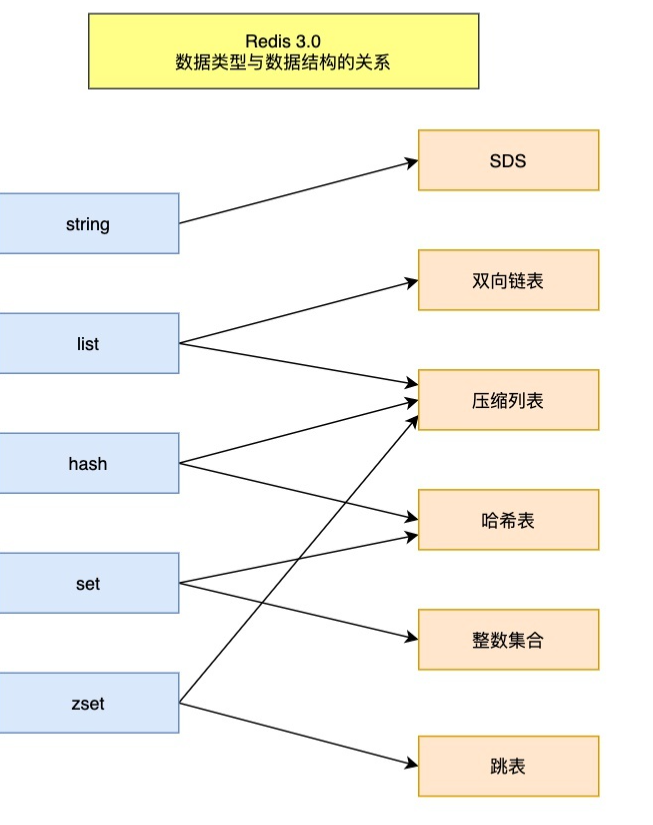
字符串 String
Redis自己构建了一种SDS(Simple dynamic string)的数据结构,用于存储字符串。
struct sdshdr{
//记录buf数组中已使用字节的数量
//等于 SDS 保存字符串的长度
int len;
//记录 buf 数组中未使用字节的数量
int free;
//字符数组,用于保存字符串
char buf[];
}
redis> SET msg "hello world"
OK
redis> APPEND msg " again!"
(integer) 18
redis> GET msg
"hello world again!"
首先, SET 命令创建并保存 hello world 到一个 sdshdr 中,这个 sdshdr 的值如下:
struct sdshdr {
len = 11;
free = 0;
buf = "hello world\0";
}
当执行 APPEND命令时,相应的 sdshdr 被更新,字符串 " again!" 会被追加到原来的 "hello world" 之后:
struct sdshdr {
len = 18;
free = 18;
buf = "hello world again!\0 "; // 空白的地方为预分配空间,共 18 + 18 + 1 个字节
}
而在执行APPEND之后, Redis 为 buf 创建了多于所需空间一倍的大小。以下为伪代码
def sdsMakeRoomFor(sdshdr, required_len):
# 预分配空间足够,无须再进行空间分配
if (sdshdr.free >= required_len):
return sdshdr
# 计算新字符串的总长度
newlen = sdshdr.len + required_len
# 如果新字符串的总长度小于 SDS_MAX_PREALLOC
# 那么为字符串分配 2 倍于所需长度的空间
# 否则就分配所需长度加上 SDS_MAX_PREALLOC 数量的空间
# SDS_MAX_PREALLOC 的值为 1024 * 1024,即1MB
if newlen < SDS_MAX_PREALLOC:
newlen *= 2
else:
newlen += SDS_MAX_PREALLOC
# 分配内存
newsh = zrelloc(sdshdr, sizeof(struct sdshdr)+newlen+1)
# 更新 free 属性
newsh.free = newlen - sdshdr.len
# 返回
return newsh
列表 List
当满足以下两个条件时,使用压缩列表ziplist实现
- 列表对象保存的所有字符串元素的长度都小于64字节
- 列表对象保存的元素数量小于512个
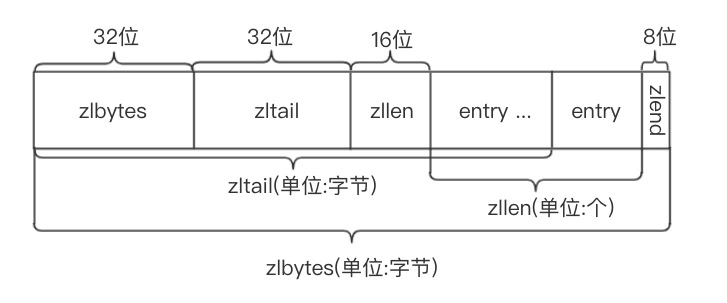
里面几个字段的意思分别是:
- zlbytes:压缩列表占用的内存字节数
- zltail:尾节点的偏移量
- zllen:列表中的结点数
- entry:节点
- zlend:结尾标识符,固定值0xFF
节点字段entry结构如下
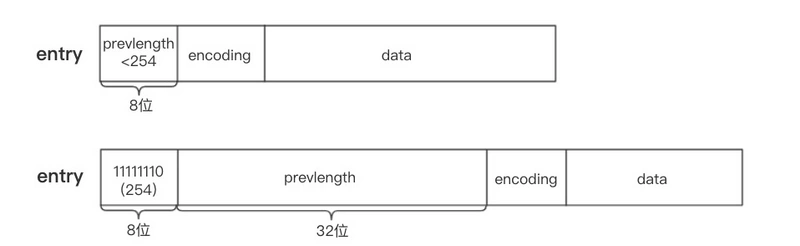
- previous_entry_length:前一个节点的长度,用于实现从表尾向表头遍历操作
- encoding:记录了数据类型(int16? string?)和长度。
- data/content:记录数据
优势:有效地节省内存开销
缺点:1、查找复杂度高
2、连锁更新:压缩列表新增某个元素或修改某个元素时,如果空间不不够,压缩列表占用的内存空间就需要重新分配。而当新插入的元素较大时,可能会导致后续元素的 prevlen 占用空间都发生变化,从而引起「连锁更新」问题,导致每个元素的空间都要重新分配,造成访问压缩列表性能的下降。
当不满足上述两个条件时,列表使用linkedlist实现
linkedlist是一个双向链表,每个entry包含向前向后的指针。插入和删除效率很高
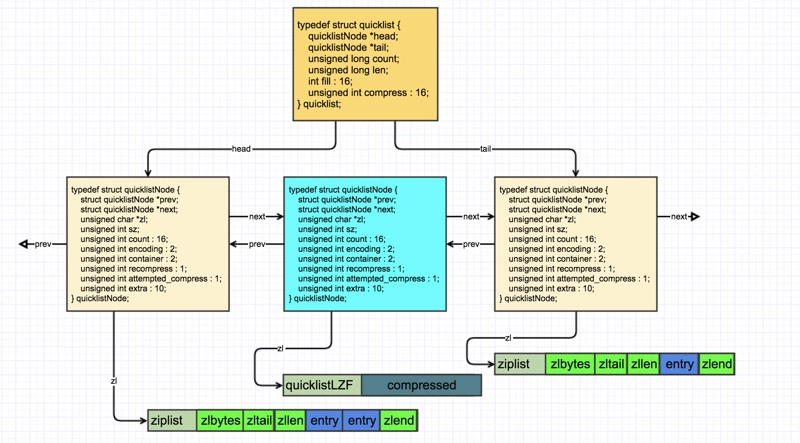
quicklist(Redis 3.2 引入)
一个由ziplist组成的双向链表。但是一个quicklist可以有多个quicklist节点,它很像B树的存储方式。是在redis3.2版本中新加的数据结构,用在列表的底层实现。
哈希
哈希底层有两种实现方式,一种是上述的压缩列表的方式,另一种是使用字典(哈希表)实现。
当同时满足一下两个条件时使用压缩列表,这也是因为压缩列表只适合节点数量不多的实现场景
- 哈希对象保存的减脂对数量小于512个
- 哈希对象保存的所有j键值对中的键和值的字符串长度小于64字节
字典的实现涉及三部分结构体:字典、哈希表、哈希表节点。其中哈希表节点保存一个键值对。
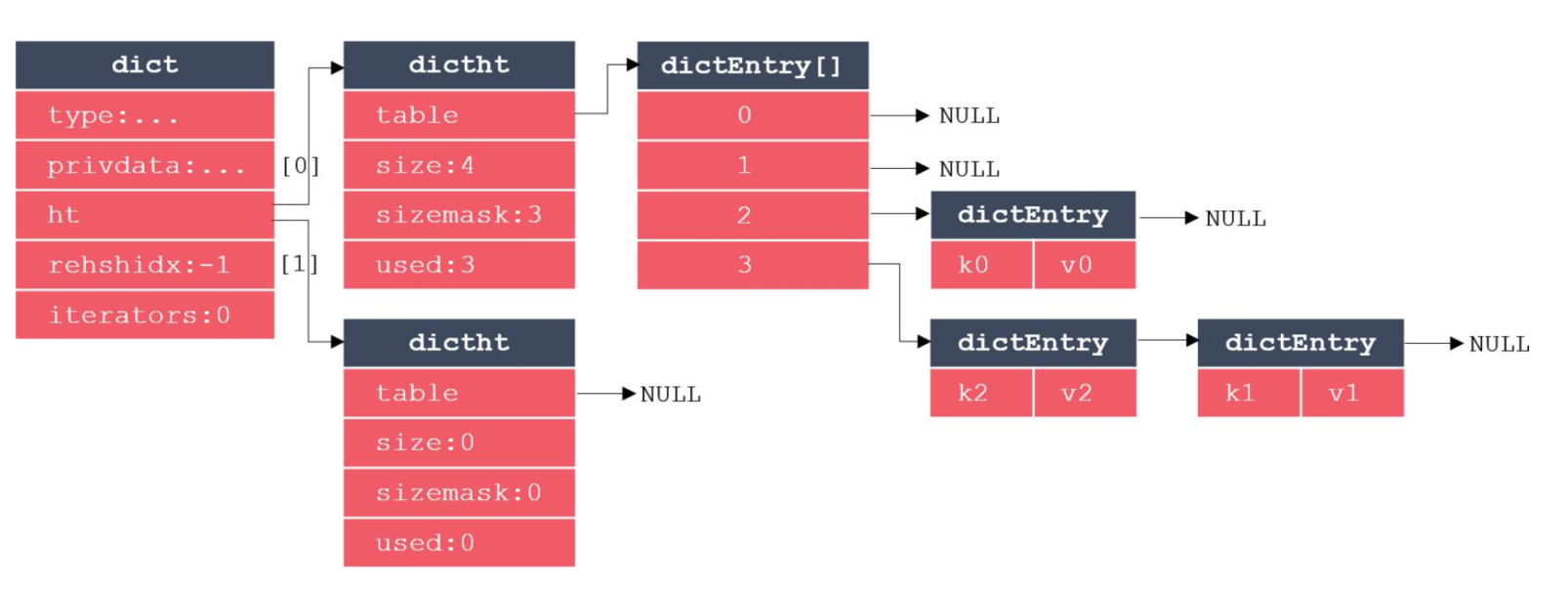
其中,dict表示字典,dictht表示哈希表,dictEntry表示哈希节点。
dicEntry是一个数组,和JDK中HashMap实现差不多,使用的是拉链法。
dictht有两个,这是为了实现扩展和收缩哈希表使用的,通过rehash方法实现。
rehash步骤:
- 为字典ht[1]哈希表分配内存空间:扩展操作,ht[1].size是第一个大于 ht[0].used*2的2^n数;收缩操作,ht[1].size是第一个大于 ht[0].used的2^n数
- 将存储在ht[0]中的数据迁移到ht[1]上
- 清空ht[0],交换ht[0]和ht[1]
触发扩容操作的条件:
- 当负载因子大于等于 1 ,并且 Redis 没有在执行 bgsave 命令或者 bgrewiteaof 命令,也就是没有执行 RDB 快照或没有进行 AOF 重写的时候,就会进行 rehash 操作。
- 当负载因子大于等于 5 时,此时说明哈希冲突非常严重了,不管有没有有在执行 RDB 快照或 AOF 重写,都会强制进行 rehash 操作。
触发收缩操作的条件:
- 当哈希表的负载因子小于0.1时,程序自动开始对哈希表执行收缩操作。
在进行rehash过程中,dict添加、查询和删除操作:
添加:添加在ht[1]中
查询:首先会在ht[0]中查询,查询不到则去ht[1]中查询
删除:ht[0]和ht[1]都要查找并删除
Set 集合
整数集合是 Set 对象的底层实现之一。当一个 Set 对象只包含整数值元素,并且元素数量不时,就会使用整数集这个数据结构作为底层实现。
typedef struct intset {
// 编码方式
uint32_t encoding;
// 集合包含的元素数量
uint32_t length;
// 保存元素的数组
int8_t contents[];
} intset;
可以看到,保存元素的容器是一个 contents 数组,虽然 contents 被声明为 int8_t 类型的数组,但是实际上 contents 数组并不保存任何 int8_t 类型的元素,contents 数组的真正类型取决于 intset 结构体里的 encoding 属性的值。比如:
- 如果 encoding 属性值为 INTSET_ENC_INT16,那么 contents 就是一个 int16_t 类型的数组,数组中每一个元素的类型都是 int16_t;
- 如果 encoding 属性值为 INTSET_ENC_INT32,那么 contents 就是一个 int32_t 类型的数组,数组中每一个元素的类型都是 int32_t;
- 如果 encoding 属性值为 INTSET_ENC_INT64,那么 contents 就是一个 int64_t 类型的数组,数组中每一个元素的类型都是 int64_t;
升级操作:就是当我们将一个新元素加入到整数集合里面,该元素的类型比整数集合现有的所有元素的类型都要长时,按新元素的类型扩展 contents 数组的空间大小。但不支持降级操作
Zset 有序集合
底层使用压缩列表和跳表实现。使用压缩列表的条件是:元素数量不超过128个并且元素长度小于64字节。
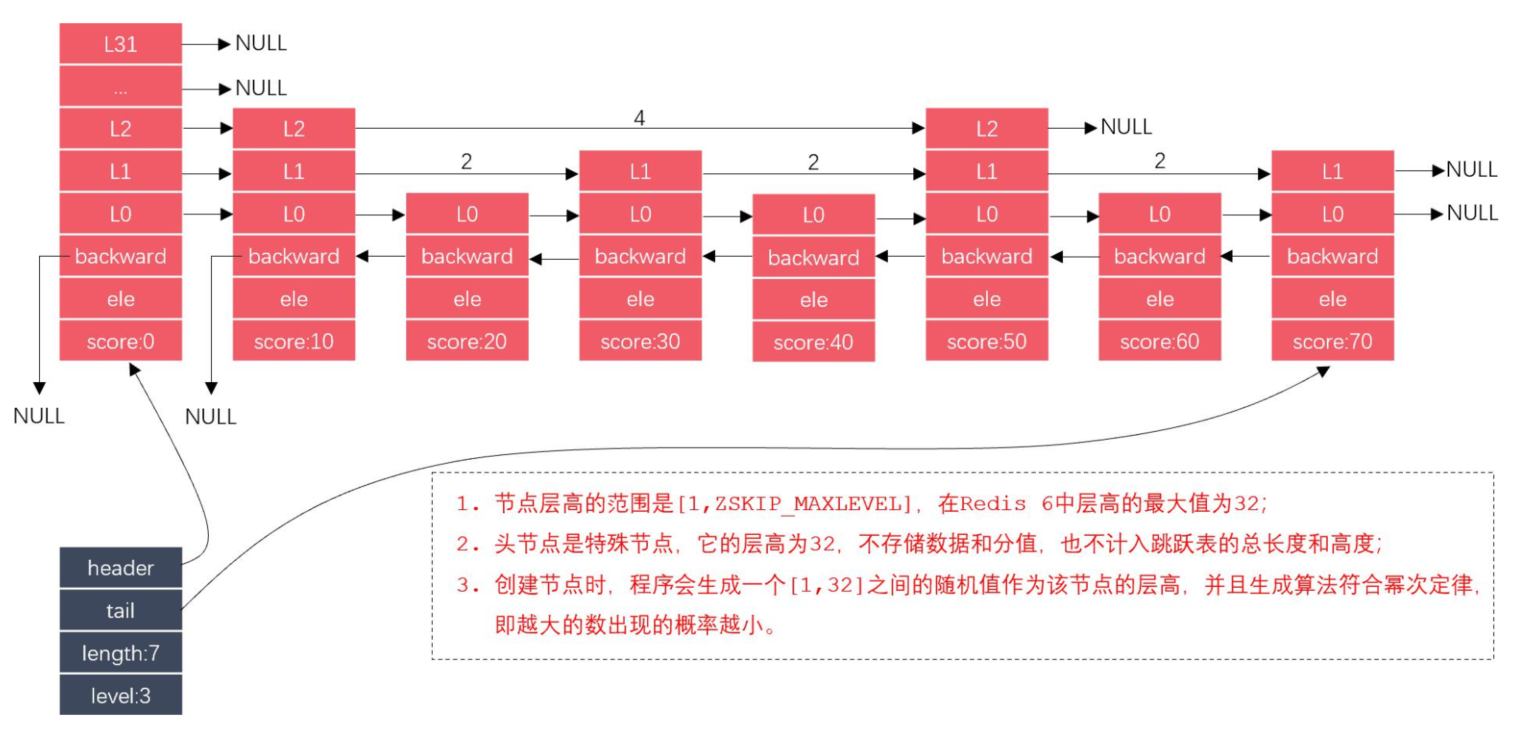
跳表实现涉及两个结构体:zskiplist和zskiplistNode。跳表优先在顶层搜索,是一种二分查找算法。
typedef struct zskiplist {
// 表头节点和表尾节点
struct zskiplistNode *header, *tail;
// 表中节点的数量
unsigned long length;
// 表中层数最大的节点的层数
int level;
} zskiplist;
typedef struct zskiplistNode {
// 后退指针
struct zskiplistNode *backward;
// 分值
double score;
// 成员对象
robj *obj;
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 跨度
unsigned int span;
} level[];
} zskiplistNode;